Data | Data Science and AI | Domains | Topics
Data Science Podcast Recommendations Rens Dimmendaal 12 Jul, 2019





Have you ever implemented your own bandit algorithm? Want to know how to get started? Read on to find out how to create simple contextual bandits from scratch, code included.
This blog is a result of a Friday hackathon (this explains the title) where some colleagues and me set out to explore contextual bandits. Our aim was to build the simplest version of a contextual bandit we could think of.
The multi-armed bandit problem originates from the hypothetical experiment of choosing the best arm on a slot machine. Not knowing which arm will give the best reward, the idea is to experimentally find out by randomly pulling arms and continuing (exploiting) to pull arms with the highest rewards.
A contextual bandit is a bandit algorithm where the reward depends on the context (also called environment). For example, assume that the pay out of the slot machine depends on the age of the person pulling the arm. Then we want to find out for each age (or age group) the arm with the highest reward. Of course, for a fair slot machine the context should not influence the outcome, but in practical applications where bandit algorithms are used the context will often have an impact.
The more context you take into account, however, the more time it takes to learn the optimal action for each context.
The application we had in mind was to recommend products to customers. Translating to slot machines this means that each product is an arm on the slot machine. We assume that the buying/click probability for each customer for each product depends on both age and wealth (this is the context that the contextual bandit should learn). Again in the context of slot machines this means that age and wealth of the person pulling the arm influences the reward.
Such a recommendation setting has many real world applications, such as the recommending of products on e-commerce websites like Bol.com and Amazon. Also the recommendation of content on e.g. Netflix or advertisements by Google are very similar.
The baseline bandit learns from historic data the overall click/buy rate per product. It always recommends the product with the highest click/buy rate, and therefore doesn’t learn after the initial training stage.
Thompson sampling, named after William R. Thompson, is a heuristic for choosing actions that addresses the exploration-exploitation dilemma in the multi-armed bandit problem. It consists of choosing the action that maximizes the expected reward with respect to a randomly drawn belief.
The bandit based on Thompson sampling (see Wikipedia’s definition above) works as follows. For each product it samples a buy/click probability based on the beta distribution learned from historic data and picks the best product accordingly. After each recommendation the probabilities are updated. As a result this bandit will keep learning since even low buy/click probability products have a chance to be chosen.
Our contextual bandit is actually a wrapper bandit as it bins age and wealth and applies a bandit of choice to each bin. That is, the problem is broken up into many sub-problems which are solved independently.
The number of bins to use is a trade-off between the flexibility to learn and the amount of data you have (or the time it takes to collect it). It is a parameter from which equal width bins are created.
To see how far off we are from the optimal performance we created a cheating bandit that uses the probabilities used for data generation to determine which products will have the highest click/buy rate for any given context. Only luck can get you better performance.
To verify the quality of the bandit algorithms we will create we need to define the system that will determine the reward for each action in each context. Using existing data sets will give us little control and therefore we chose to generate data such that we can create a variety of different products with different rewards and varying impact of the context.
For each product we choose a specific distribution (we use wildly varying shapes) that determines the expected reward for each context. E.g. for potatoes the click/buy probability is max(0, age – wealth^2).
From these distributions we can then sample training data. And after training we can sample as many test records as we want to fairly determine the performance of each bandit.
These are the steps to sample a single record:
Below a sample of generated data. Each record represents how a customer with a specific context (age and wealth) would react to each of the products, i.e. would they buy/click.
For example, for the first record, first the age and wealth are randomly sampled between 0 and 1 to be 0.82 and 0.33, respectively. Then for each of the products we look at the chosen conditional probabilities to sample True or False for the buy/click action. For potatoes the conditional probability for the given age and wealth is 0.82-0.33^2 = 0.71. We thus sample True with a probability of 0.71 and False with a probability of 0.29.
Below you see a visualization of the chosen conditional buying probabilities for each of our products based on age and wealth.
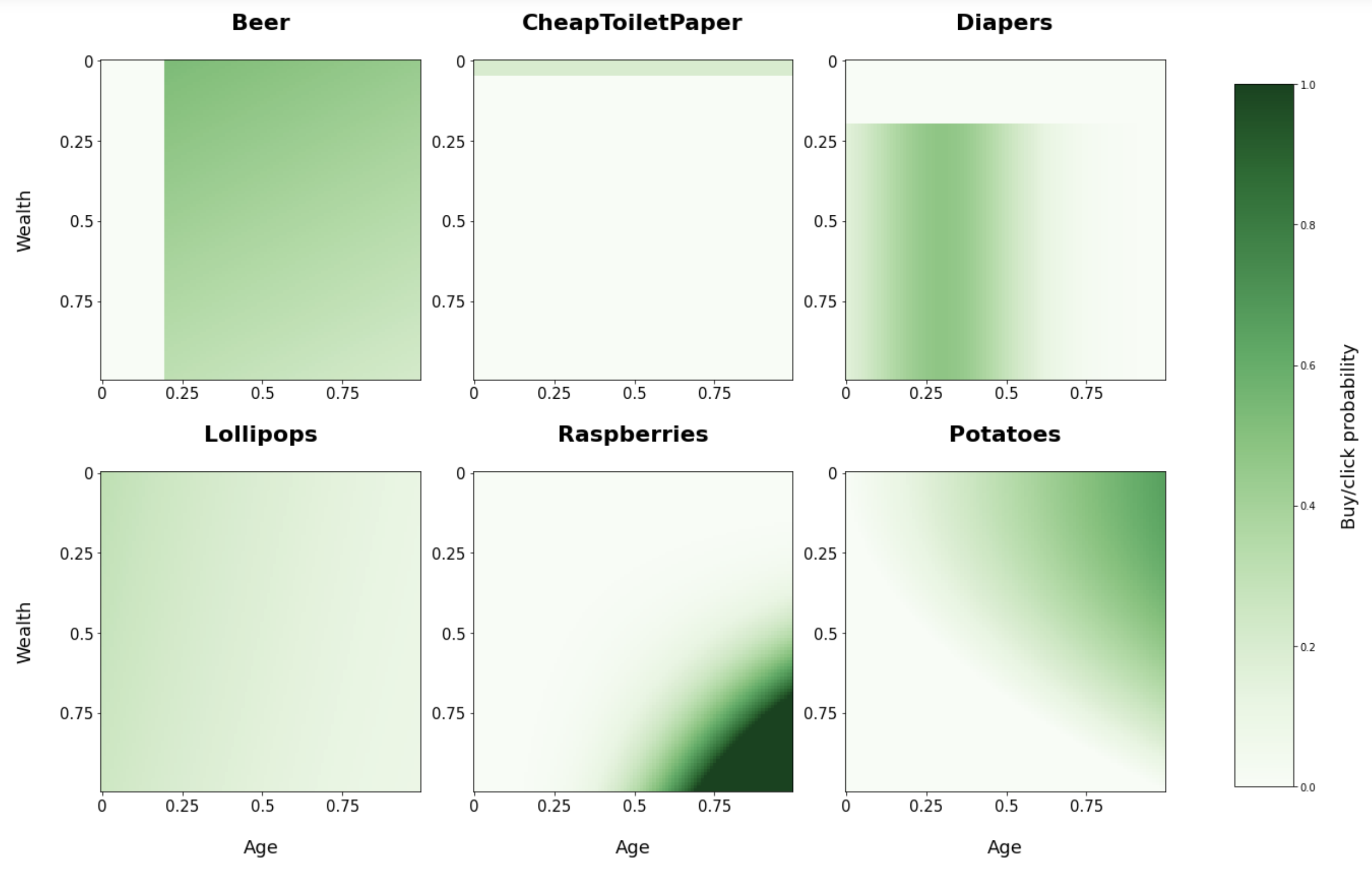
From these plots you can see for example that raspberries are more likely to be bought by old and wealthy people. And cheap toilet paper only with a small probability by very poor people and not at all by the rest.
We created a simulator to score the different bandits. Each bandit has the option to train on some historic data (1,000 records). Also, each bandit can either be vanilla or the contextual variant with binning. Below the results (sorted on performance) on 10,000 recommendations.
| Bandit | Training | Contextual | Buy/click (%) |
|---|---|---|---|
| Cheating | – | – | 49.91 |
| Baseline | Yes | Yes | 42.53 |
| Thompson sampling | Yes | Yes | 42.14 |
| Thompson sampling | No | Yes | 40.26 |
| Baseline | No | Yes | 30.45 |
| Baseline | Yes | No | 30.68 |
| Baseline | No | No | 29.55 |
| Thompson sampling | Yes | No | 30.29 |
| Thompson sampling | No | No | 28.79 |
Looking at the performance of the cheating bandit (almost 50%), a conversion of 43% for the runner-up seems pretty good. Especially taking into account how simple these bandits are. They can be implemented in only a few lines of code.
We’ve created some simple bandit algorithms and created context aware variations of them. On some generated data we concluded that these simple algorithms perform pretty decently.
Are you working on a recommendation problem and are you considering using bandits? I would be interested in hearing your experience. Happy coding!

