
Data Governance | Topics
Stop Blaming Your Data 
godatadriven 21 Dec, 2020





In previous post on Data & AI organizational design I have introduced the design principles from the book Team Topologies and discussed these principles with respect to some important aspects of a Data & AI organization:
In this blog I will have a look at three companies, different in size and AI maturity, and explore what the organizational design could look like. For the first company we will consider 3 different scenarios, the second company just one and the third company will be very familiar to you. We assess the designs using the design principles as discussed in previous blog.
The conclusion of previous blog was that the four fundamental team topologies, three team interaction modes and the design principles from the book give us both the verbal and visual (see figure 1) language to discuss organizational design more effectively and specifically. Not one single fixed organizational design will fit every organization, not one single fixed organizational design will fit a single organization throughout time.
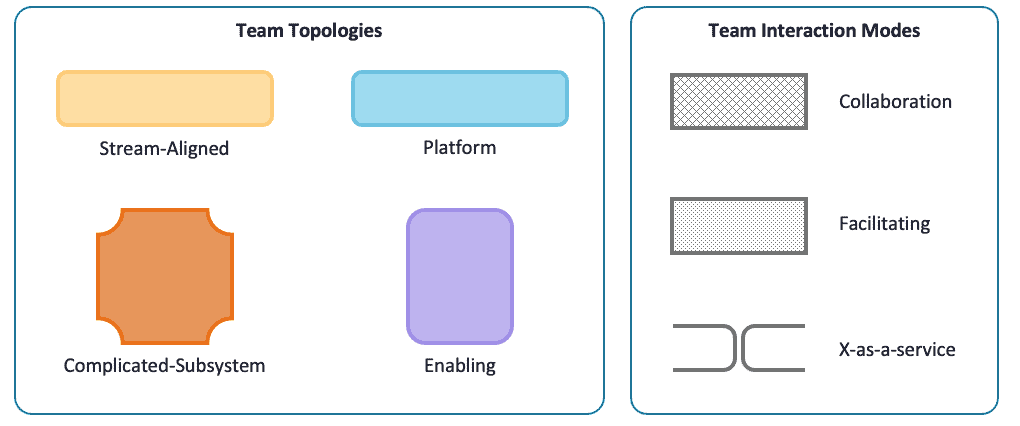 Figure 1: Team Topologies legend
Figure 1: Team Topologies legend
This company is working on AI use cases for a couple of years now. It started with marketing analysts working on an innovative project on next best action models in the sales funnel, supported by external data scientists. Data analysts from the BI team within IT helped with getting the required data. Results were promising and with support from IT a temporary solution was found to run the model in production. The marketing department continues experimenting by hiring a junior data scientist. The supply chain operations department also hired a junior data scientist to use historic sales and operations data to improve forecasts for next week’s transport volumes.
Since then, the opportunities of AI have gained much attention across the company and many ideas on potential AI use cases exist. Some of these use cases may be kick-started with the help of external data and AI experts. But management realizes that AI is here to stay and having an own AI capability is a more optimal solution in the long run, both from a cost and internal knowledge development perspective. That is why management has decided to include Data & AI as a key competence in their strategy for the next couple of years.
Business domains start hiring for data expertise, in line with the key strategic competence as Data & AI is defined recently. For some business domains, analytics is still very new, they have other more urgent data issues, so they decide to hire data analysts to support the rest of the department with the insights they need. The Marketing department hires a data engineer for the Next Best Action team.
After some time all business domains are pleased with the new data experts in their teams. The analysts are very busy helping colleagues with all kind of data requests and sometimes they can even introduce new ways of using the data and generate innovative insights.
The engineers have made some progress, but due to many urgent requests from analysts and scientists, many workarounds are implemented.
Initially the data scientists have worked on exciting experiments, but the product team members lack the time and knowledge to really unlock the potential of AI and moreover, they have other priorities in further developing the online services. The data scientists turn their time and attention towards helping colleagues outside of their product team with all kind of data related questions.
 Figure 2: Scenario 1.1
Figure 2: Scenario 1.1
This is definitely Conway’s Law in action: uncoordinated efforts with scattered and quite junior data experts working on their own projects lead to point solutions and a patchwork of pragmatic implementation approaches. There is no platform team guiding and facilitating implementation of data and machine learning pipelines according to engineering best practices. New tools and technologies appear constantly in the data world, and without proper senior guidance, data experts may be tempted to introduce these new tools regularly, further extending the engineering patchwork.
Another effect of the scattering of data experts is the lack of joined knowledge development. No community or team exists to facilitate this like an enabling team would do.
Since the company is relatively small, the few product teams will have quite a broad scope of components and services they are responsible for. The data and/or AI part within this scope may be small. This leads to a lot of overhead and communication within the team unrelated to the work of the data scientist.
Strong communication lines required for value creation should be reflected in team structure, aiming at team autonomy. One could argue that this communication design principle applies in reverse for this product team. The data scientist is included in a lot of communication (e.g. refinement meetings) with limited contribution/connection to the work of the data scientist. The time available for value creation is reduced as a consequence. This leads to the idea that this team might not be the optimal place for the data scientist. As the AI use case moves further down the AI solution life cycle, and communication needs with the rest of the team decrease, this argument will get more and more relevant.
Next to identifying Data & AI as a strategic competence, in this scenario the CIO argues that this competence should be centrally developed. This way, hiring can be done with respect to balancing seniority and expertise in the team of data experts. There is budget for a cloud platform and to hire 8 additional data and AI employees. The CIO decides to form a Data & Analytics product team within IT and the existing data scientists from marketing and supply chain will join the new team.
Hiring and getting used to each other within the new team take some time, but with help from some external consultants, within half a year, the team starts getting into a flow. Data engineers work closely with the IT BI team on preparing new data sources for BI and AI. With the IT cloud team they are establishing a cloud data/BI/AI platform. Analysts and data scientists work together with various business domains and product teams on several experiments, projects and ad-hoc requests.
Every 2 weeks there is a sprint planning and refinement meeting for the entire Data & Analytics product team which takes almost a full day. The number of concurrent activities is impressive and, looking at the team’s backlog, will grow even further. The PO of the team has a full time job managing all stakeholders throughout the company. Playing down expectations on both feasibility and capacity, and setting priorities is becoming a constant struggle for the PO. To complicate matters even more, data analysts and data scientists become famous throughout the company for their all-round data skills, and colleagues find ways to get time of the data experts to get some ad-hoc stuff done, bypassing the PO in doing so.
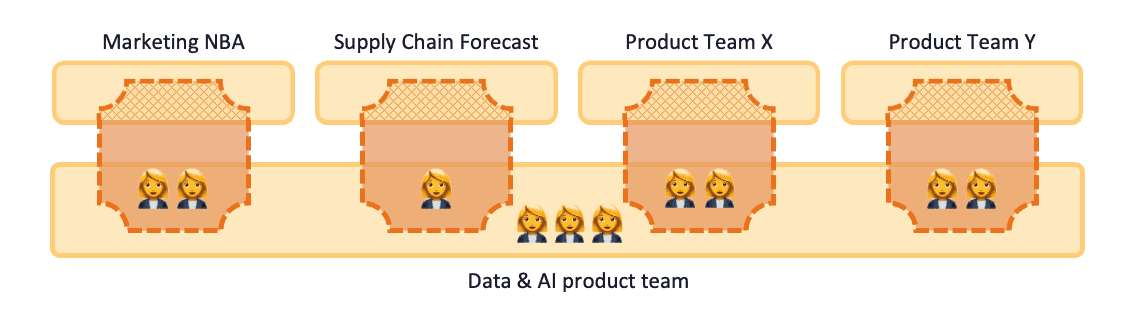 Figure 3: Scenario 1.2
Figure 3: Scenario 1.2
Data analysts/scientists benefit from the joined forces with data engineering on building a platform together. After the initial learning curve they will be able to experiment and develop much faster using engineering best practices and the available templates for data and machine learning pipelines. This results in a harmonized usage of a single data platform. Clearly, the data system’s architecture benefits from having the data experts in one team, as is predicted by Conway’s Law.
A lot of communication is required between the data experts and business/product teams. The interaction mode between the Data & AI product team and the rest of the organization can be characterized as extensive and many to many, resulting in very limited autonomy of the Data & AI product team. A Data & AI product team being completely autonomous in this setup would actually be really strange, since one cannot expect this team to build business relevant solutions, with no communication at all to the business.
In practice it turns out to be very challenging to ensure adoption of these solutions by business teams, due to the distance between data scientist and business stakeholders during the development process. And time spend, by resources which were scarce already, on AI solutions not being used, because of limited fit to actual business requirements, is time not very well spend.
On top of the "between teams"-communication load, the team has regular meetings like every product team has. While the team is working on many different projects and task, each data expert is only working on a handful of them. During planning and refinement meetings, most of the time is spent on projects and task of other team members. This enables including everyone’s knowledge and experience in all the team’s work, but there are more effective ways of facilitating that kind of communication. The Data & AI product team setup, working on many tasks, projects and business domains, again leads to a communication load on every data expert. And this time, not related to the work of the experts themselves. Like in scenario 1.1, the reversed communication design principle applies, suggesting that the current team design is suboptimal, from a "team internal"-communication point of view.
The high internal and external communication loads suffered by both the PO individually and the team as a whole makes this team design a challenging one for attaining high team productivity. Even though this productivity is improved by working together on one platform.
This scenario starts similar to the previous one, except that the team of Data & AI experts is not intended to operate as an autonomous product team, having own sprint planning meetings and so on. Instead, a "home base" team is formed, from which data experts will be allocated to specific projects or product teams for a certain period of time. This allocation will be part-time, since a percentage of the time (10% to 20%) of the data analysts and scientists will be reserved for shared development of knowledge, skills and infra the team will work on.
The data engineers spend up to 50% of their time within the own team, to introduce engineering best practices, templates etc. for both data and machine learning pipelines and to cooperate with the BI team to migrate the on-premise data warehouse to the cloud, making the data available for both BI and AI applications.
Instead of spending all budget on data engineers, analysts and scientists, two analytics translators (AT) are hired. The ATs liaise with business teams, collect all ideas and requests around data and AI, discuss priorities with management and plan allocation of data expertise to projects and product teams.
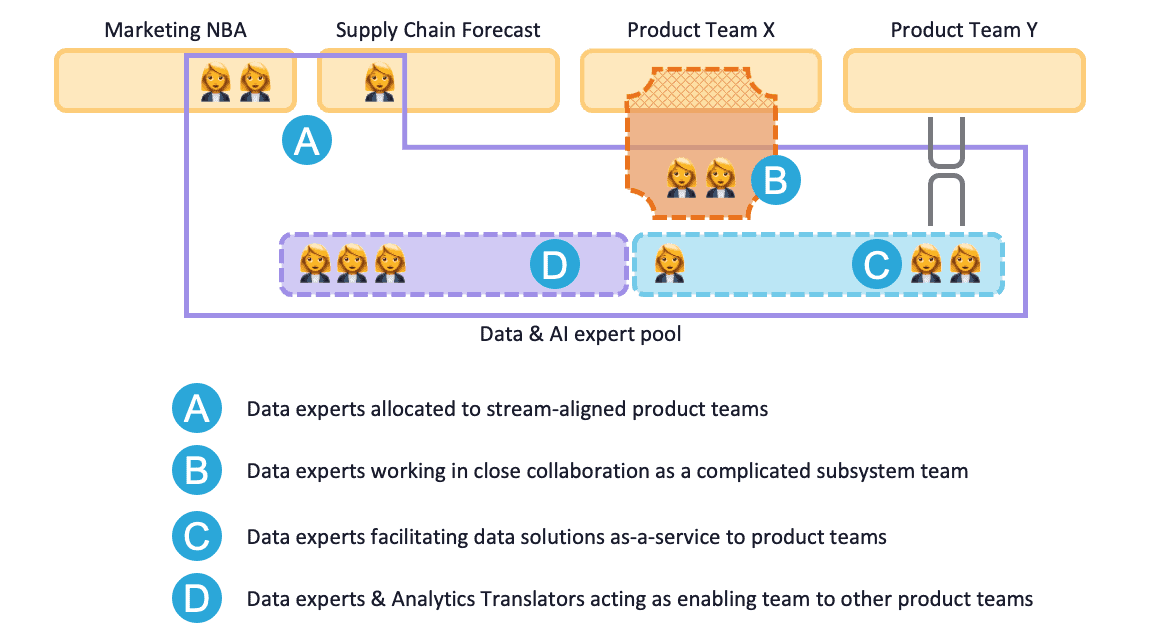 Figure 4: Scenario 1.3
Figure 4: Scenario 1.3
This scenario arranges for a couple of improvements compared to previous one, all related to communication, both within the team as with other teams. Communication with other teams is about working on specific use cases, communication within the team is about developing the platform and knowledge to facilitate development of Data & AI solutions. In their temporary time at the business or product team the data experts are part of a stream-aligned team, during their time in their own Data & AI team they are part of a platform/enabling team.
They will work in the stream-aligned team for as long as it is relevant, preferably moving physically close to that team for several days a week to ease communication (A in figure 4). Planning and refinement of work will be done within the business or product team, not within the more general facilitating Data & AI team. As work progresses through the AI solution life cycle and the need for communication decrease, the interaction mode may change to collaboration. The data experts working on the AI solution can form a complicated subsystem team for the stream-aligned business product team (B in figure 4). Later on this may change to the platform team topology and as-a-service interaction mode (C in figure 4) when the solution is ready for production.
The amount of communication needed acts as an indicator for "scaling down topology" from the stream-aligned team to a complicated subsystem team and platform team later on, to prevent e.g. unnecessary overhead communication in the AI solution consuming stream-aligned product team.
As mentioned above the activities within the Data & AI team are related to platform and knowledge development. Knowledge development of the data experts themselves, but also for the rest of the organization, working to improve data & AI literacy and awareness of everyone.
There is not one single team topology the data experts operate in. Rather the individual data expert changes topology and interaction mode in time adapting to the required communication of the task at hand. Instead of regarding this to be confusing, the specific labeling of the optimal team topology and interaction mode per task makes the required communication, dynamics and challenges transparent. Only then the cognitive load of the team and its members can be managed properly.
The analytics translator (AT) is responsible for most of the communication, bridging the gap in knowledge, skills and priorities between AI complicated subsystem teams and stream-aligned business/product teams. Furthermore the AT works on increasing data literacy around the company by introducing business teams to basic analytics and data operations, reducing the ad hoc workload of data experts. This way the AT is acting as enabling team (D in figure 4) for simpler data related task towards business (together with other currently non-allocated data experts), as PO for medium difficulty tasks done in complicated subsystem teams, and as (facilitator to the) resource manager for the larger projects where data experts get allocated to stream-aligned teams.
This company is much larger compared to the one from case 1. Even though the setup used to be like scenario 1.3, which was a good fit to the scale of the data and AI activities of that time. With growing number of customer-facing AI applications and data experts, dedicated AI resources emerged in several business teams.
The central Data & AI team still exists, providing AI services like they did before, but nowadays mainly to departments and teams without dedicated data experts or e.g. to temporarily support other data scientists on large projects.The data engineers have moved to a data engineering team, focusing on both data and cloud engineering for BI and AI purposes. The team provides data preparation pipeline templates and advanced cloud workspaces as-a-service to advanced analysts and data scientists.
Several AI applications have made it all the way through the life cycle up to production and a ML engineering team has been formed to research new tools and technology on this topic, establish best practices for running and monitoring models in production and support product teams with trainings and e.g. code reviews.The data analysts and data scientists have initiated an Analytics Community in which they gather to share their latest successes and to work on knowledge development.
Although the current design, from both an organizational and IT architecture point of view, is solid and works pretty good, next improvements are being planned. Data governance of the entire IT operational landscape has matured and product teams will soon be able to take ownership of data preparation, documentation and monitoring for BI and AI purposes.
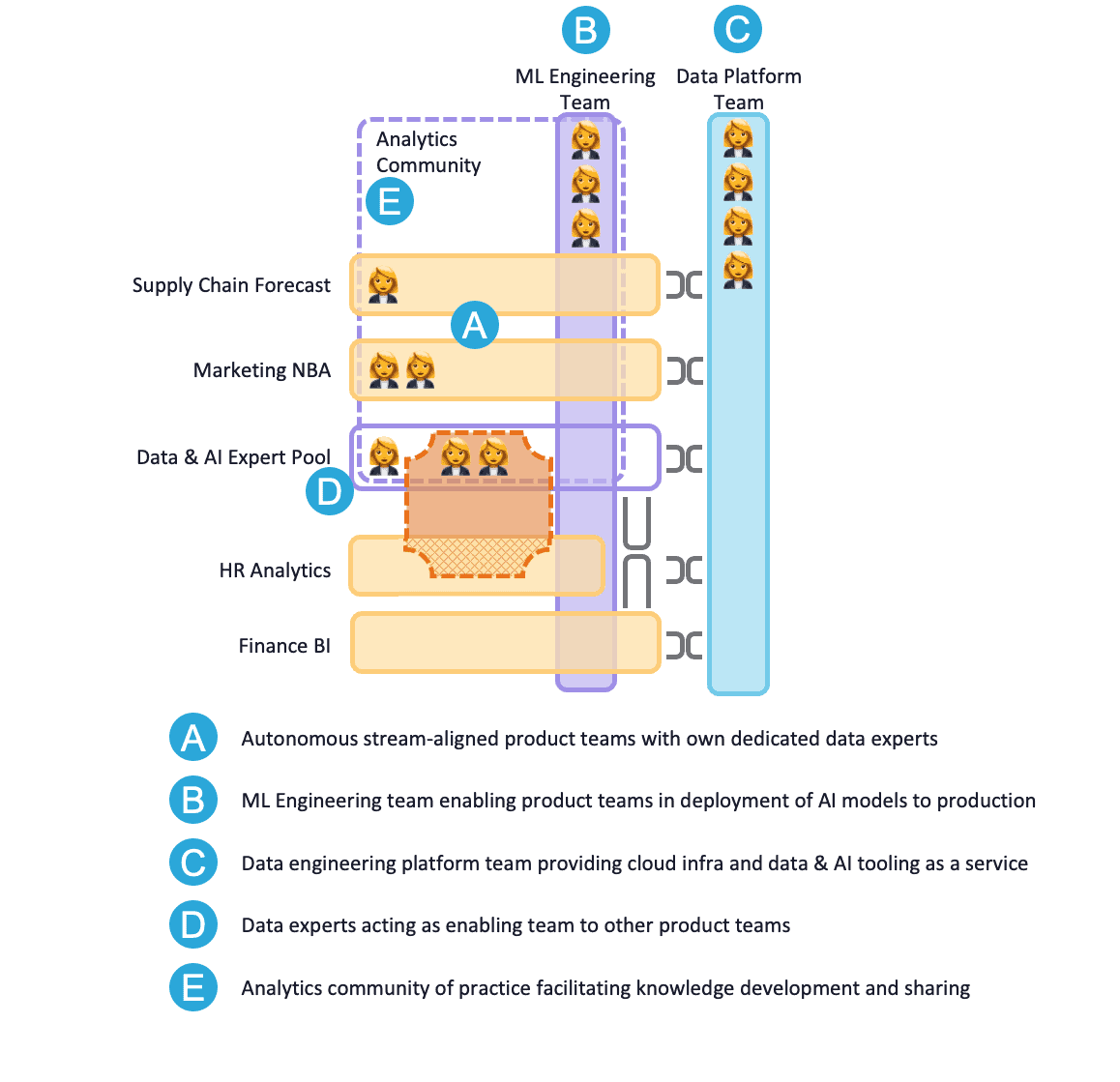 Figure 5: Scenario 2
Figure 5: Scenario 2
Well, of course the main purpose of this scenario is to outline how a large AI organization could look like. The key difference with previous scenarios is that, due to the increased demand and budget for AI solutions, product owners can justify having full time all year round data experts in their teams.
The larger part of data and AI work is being done autonomously in product teams around the company (A in figure 5), with support from the ML engineering enabling team (B in figure 5) and the data engineering platform team (C in figure 5). A key factor for product teams to be successful with developing AI solutions within the team is having a PO who understands the specifics of the AI solution life cycle, from ideation up to production. The Analytics Translator Training is well suited for POs for this purpose.
The cognitive load of stream-aligned teams with data experts and the central Data & AI expert pool (D in figure 5) is reduced by the data engineering platform team and the ML engineering enabling team. This way the tools and technology during development and production are available as-a-service from the platform team, and the knowledge on everything around model deployment to production can be obtained from the enabling team. As a result the data analysts and scientists can focus on their use cases and their specific expertise instead of having to learn a lot on technology and engineering.
Compared to scenario 1.3 no physical team exist anymore to facilitate knowledge development. The data experts founded a Community of Practice for this purpose (E in figure 5). Another way of doing this would be to introduce an Analytics Chapter with a dedicated lead, empowering the analytics community even more. The chapter lead will take care of hiring, onboarding and coaching data experts for more continuity in data talent management and a balanced data and AI workforce across all product teams in terms of seniority and expertise.
The operational load of managing many data pipelines in production by the platform team, providing amongst other services data-as-a-service, is getting too much and too complex. In running the pipelines, many dependencies may arise; again Conway’s Law in action, one team working on providing data-as-a-service for many data sources will lead to a system design with one large complex component delivering the data. By moving responsibilities on data preparation, documentation and monitoring upstream towards the data generating product teams, the data engineering platform team is released from very detailed tasks on specific data sources, so it can focus on its facilitating tasks. Furthermore the data system as a whole will get a bit more disentangled, according to Conway’s Law, making managing the data pipelines more clear.
You might recognize some characteristics and organizational designs of the companies from above two cases, but each company has its own history, details and vision leading to the current data & AI organizational structure.
Please note that none of the examples in this blog should be considered to be the single best solution any organization should aim for. The objective of this blog was to show how one can assess the advantages and disadvantages of certain organizational designs, using the theory from the book Team Topologies. Your organization should aim for conducting an assessment like that, and deriving your own best Data &AI organizational design as a result.
Would you like to discuss the organizational design for data and AI teams specifically for your organization and assess different scenarios for potential improvements? Please contact us!
Our AI maturity scan can be used to assess specific aspects of your company. You will get recommendations to get your company to the next level of AI maturity and can be used as input for your company’s AI Strategy and AI organizational design.
