
Dennis Vink 15 Jul, 2019





AWS SageMaker provides a platform for developing, training and deploying machine learning models. In one sentence, the training works by providing a Docker image holding a train executable, which AWS SageMaker executes to run your training job. The input and output data should be delivered in a certain directory, for the work to align correctly. You define the underlying instance type and AWS will spin up the resources, run the job, write output, and tear down again.
Recently I was faced with the challenge of a large training job where one single instance didn’t do the job anymore, both in terms of processing power and (expected) time to complete. A quick Google search led me to two resources:
While both resources use pre-built AWS models (and the 2nd resource even mentions training on multiple machines is a "non-trivial process"), both don’t go into detail how to really do distributed processing with SageMaker. However, I had enough reason to believe it would be possible to run a DIY training job in distributed fashion. In hindsight, the process was indeed non-trivial and led me down a rabbit hole, hence the reason for this blog post.
Before going into distributed training, let’s shortly recap how DIY training with AWS SageMaker works (also check out my previous blog post on DIY SageMaker models). By "DIY" I’m referring to providing your own training Docker image.
SageMaker requires an executable in the Docker image named train, which it will call for training. Inside this training job you can perform whatever code you like. To provide data to the job, you configure the InputDataConfig key in the job’s configuration, which holds a list of so-called "Channels", where each Channel is mounted inside the training container to /opt/ml/input/data/[channel name]. For example, say you want to provide input data which is stored on S3:
{
"TrainingJobName": "my-training-job",
...
"InputDataConfig": [
{
"ChannelName": "my-input-data",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://my-bucket/training-data/"
}
}
}
]
}The configuration above tells SageMaker all S3 objects prefixed with s3://my-bucket/training-data/ should be mounted to the training container. The ChannelName property is set to "my-input-data", so the data will be accessible inside the container on /opt/ml/input/data/my-input-data. Figuring out all the available settings can be cumbersome and often requires meticulously reading the documentation.
Just like input data, the output data is also expected in /opt/ml, in /opt/ml/model/.... After the training completes, anything inside this directory will automatically be saved back to S3 with the following configuration:
"OutputDataConfig": {
"S3OutputPath": "s3://my-sagemaker-output/output-path"
}Visually, this is the process that SageMaker facilitates:

The example above runs a single Docker image, so how do we run multiple? This could be desired when your training job can be easily split into multiple smaller jobs and you require lots of computational power.
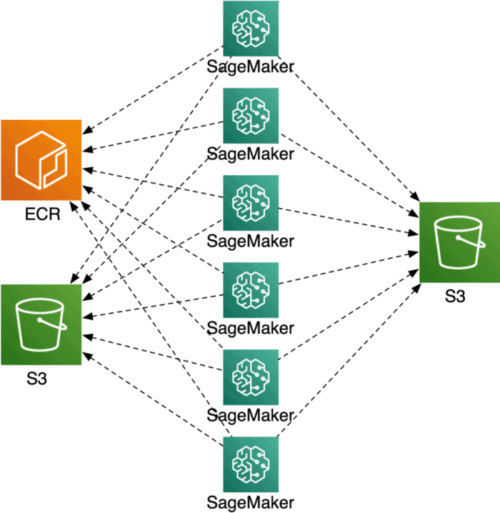
How to distribute work over multiple SageMaker training instances?
First, take a look at the ResourceConfig section in the SageMaker configuration. For example:
"ResourceConfig": {
"InstanceType": "ml.c5.4xlarge",
"InstanceCount": 10,
"VolumeSizeInGB": 5,
},All three configuration keys (InstanceType, InstanceCount, and VolumeSizeInGB) are required. Simply set InstanceCount to a value larger than 1 to create multiple instances.
In the configuration of your input data sources, you must decide how to distribute the input data to the training instances, with a key named "S3DataDistributionType":
{
"TrainingJobName": "my-training-job",
...
"InputDataConfig": [
{
"ChannelName": "my-input-data",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://my-bucket/training-data/",
"S3DataDistributionType": "FullyReplicated"
}
}
}
]
}The value of S3DataDistributionType can be either "FullyReplicated" or "ShardedByS3Key", where FullyReplicated will make a copy of the given dataset available in every instance, and ShardedByS3Key will copy [# of data files]/[# of instances] pieces of the data to every instance. So if your input data contains 20 files and you have 6 instances, each instance will receive 20/6=3.33 files, where some instances receive 3 files and some receive 4, depending on the key of the file.
Every individual instance will run the training job on the data supplied in the instance, and write the output to /opt/ml/model. After completion of all training jobs, the data is then collected by Amazon and saved inside a single file named model.tar.gz. With S3OutputPath set to "s3://my-sagemaker-output/output-path", the full output path will be:
s3://my-sagemaker-output/output-path/[sagemaker job id]/output/model.tar.gzWhere model.tar.gz holds all output files, stored inside each individual training instance. So, if you require your output to be one single file, you will have to make an additional post-processing step in which you extract all the output files from model.tar.gz, and combine these into a single result file.
If the nature of your training job is such that it can train on individual chunks of data, you will be okay with splitting your input data into pieces and distributing these automatically with S3DataDistributionType set to ShardedByS3Key.
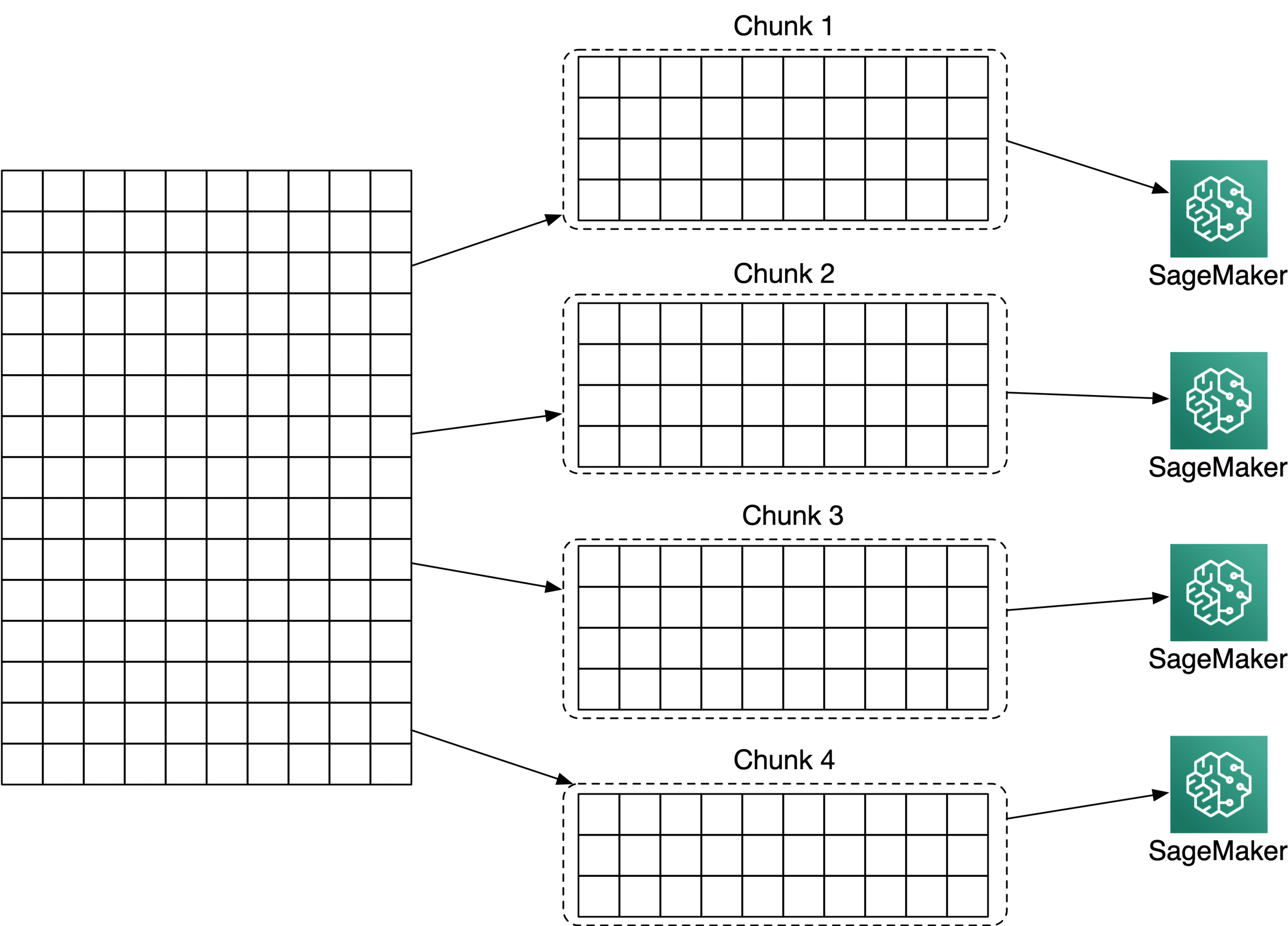
If your input dataset is "processable" in separate chunks, you can do so in a preprocessing step and distribute these to SageMaker instances with "S3DataDistributionType": "ShardedByS3Key".
However, say your training job involves a large matrix like above over which you want to compute the cosine similarity between all rows. While such a computation can be split into chunks by having each instance cover only a subset of the rows, each instance does require access to the full dataset. You can supply the full matrix to every instance by setting "S3DataDistributionType": "FullyReplicated", and determine inside each instance who will do what. In order to determine which instance will process which part of the matrix, let’s take a closer look at the available information inside a SageMaker training instance.
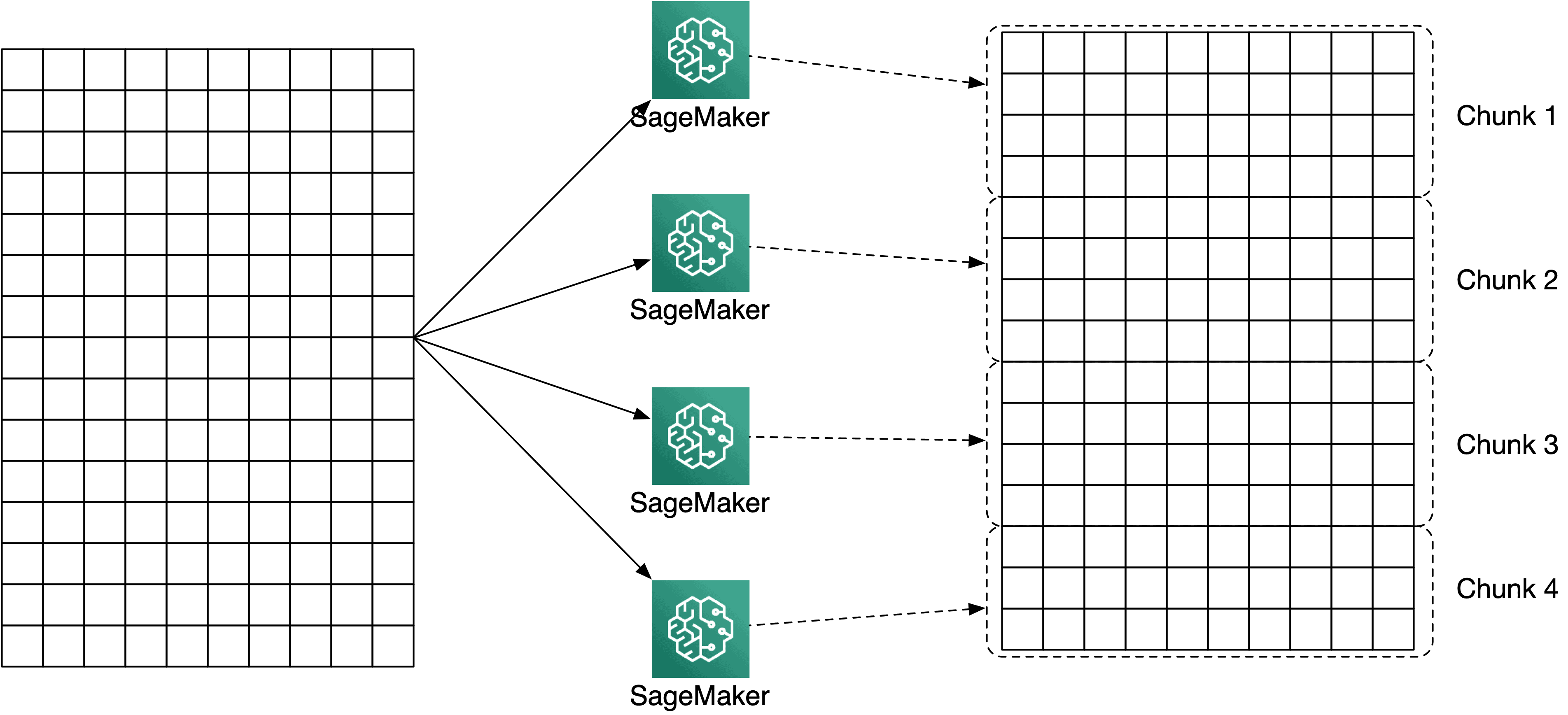
If each training instance requires the full dataset for processing, you can send the dataset to each instance with "S3DataDistributionType": "FullyReplicated", and determine inside the instance which part of the input dataset the given instance will cover.
Each SageMaker training instance holds a number of environment variables and files we could apply for our use. Printing all environment variables inside a training instance gives us the following information:
{
"PATH": "/opt/conda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"HOSTNAME": "ip-10-4-9-44.eu-west-1.compute.internal",
"ECS_CONTAINER_METADATA_URI": "http://169.254.170.2/v3/6214c0a1-6ca6-4249-9553-d999154dd547",
"AWS_EXECUTION_ENV": "AWS_ECS_EC2",
"AWS_REGION": "eu-west-1",
"DMLC_INTERFACE": "eth0",
"NVIDIA_VISIBLE_DEVICES": "void",
"TRAINING_JOB_ARN": "[my training job ARN]",
"TRAINING_JOB_NAME": "[my training job name]",
"AWS_CONTAINER_CREDENTIALS_RELATIVE_URI": "/v2/credentials/5bd0f5f7-304a-415f-9523-4493ec3f1360",
"LANG": "C.UTF-8",
"LC_ALL": "C.UTF-8",
"HOME": "/root",
"KMP_DUPLICATE_LIB_OK": "True",
"KMP_INIT_AT_FORK": "FALSE",
}Inside /opt/ml, there are also a number of useful files:
.
└── opt
└── ml
├── input
│ ├── config
│ │ ├── hyperparameters.json
│ │ ├── init-config.json
│ │ ├── inputdataconfig.json
│ │ ├── metric-definition-regex.json
│ │ ├── resourceconfig.json
│ │ ├── trainingjobconfig.json
│ │ └── upstreamoutputdataconfig.json
│ └── data
│ ├── my-input-data/
│ └── my-input-data-manifest
├── model/
└── output
├── data/
└── metrics
└── sagemaker/The json files in /config hold configuration either automatically supplied by Amazon, or configured by yourself in the training job configuration. To give an example of the contents of these files, here are the contents in one of my training jobs. However, these obviously depend on what you’ve configured in your training jobs:
hyperparameters.json
Contains: Hyperparameter configuration
Example: {}
trainingjobconfig.json
Contains: The training job configuration supplied to SageMaker
Example: {"TrainingJobName": "...", ...}
inputdataconfig.json
Contains: The input data configuration supplied in the training job configuration
Example: {'my-data': {'TrainingInputMode': 'File', 'S3DistributionType': 'ShardedByS3Key', 'RecordWrapperType': 'None'}, ...}
upstreamoutputdataconfig.json
Contains: Unknown
Example: []
metric-definition-regex.json
Contains: Metric definitions
Example: []
resourceconfig.json
Contains: Information about all instances
Example: {'current_host': 'algo-8', 'hosts': ['algo-1', 'algo-2', 'algo-3', 'algo-4', 'algo-5', 'algo-6', 'algo-7', 'algo-8', 'algo-9', 'algo-10'], 'network_interface_name': 'eth0'}
init-config.json
Contains: Different information about job configuration
Example:
{
"inputMode": "FILE",
"channels": {
"my-input-data": {
"s3DataSource": {
"s3DataType": "S3_PREFIX",
"s3Uri": "s3://my-bucket/training-data/",
"s3DataDistributionType": "FULLY_REPLICATED",
"attributeNames": None,
},
"fileSystemDataSource": None,
"compressionType": "NONE",
"recordWrapper": "NONE",
"shuffleConfig": None,
"inputMode": "FILE",
"sharded": False,
},
},
"checkpointChannel": None,
"hostConfig": {"clusterSize": 10, "hostNumber": 8},
"enableDataAgentDownloads": False,
"jobRunInfo": None,
}The resourceconfig.json (also init-config.json) holds exactly the information required:
<code>{'current_host': 'algo-8', 'hosts': ['algo-1', 'algo-2', 'algo-3', 'algo-4', 'algo-5', 'algo-6', 'algo-7', 'algo-8', 'algo-9', 'algo-10']}
From inside the training job we can determine how many hosts were configured, plus which host is currently running. With a small Python script, we can determine the subset of rows which the given instance will cover:
input_dataset = pd.read...
with open("/opt/ml/input/config/resourceconfig.json") as f:
resourceconfig = json.load(f)
n_hosts = len(resourceconfig["hosts"])
current_host = resourceconfig["current_host"]
current_host_idx = resourceconfig["hosts"].index(current_host)
total_rows = input_dataset.shape[0]
start_row = round(current_host_idx * total_rows / n_hosts)
end_row = round((current_host_idx + 1) * total_rows / n_hosts)Distributed training as described above will be suitable in case your input dataset isn’t too big, but requires lots of compute power. The input dataset will be copied to each instance, which requires some network usage and storage for every instance, so ideally you’d want to minimize the input dataset size.
Second, there is no inter-container communication, so this is only applicable if your job doesn’t require to do so, e.g. no shuffling is required, and it’s fine to merge end results back together afterwards.
In my case, I had to perform a very large cosine similarity computation over all rows of a very large matrix. For various reasons, we decided not to go with EMR & Spark, so I started investigating distributed processing with SageMaker. I was pleasantly surprised by the performance of the system once I got all the bits and pieces to work. I started with multiple ml.c5.2xlarge instances, expecting somewhat similar performance per chunk as to my Macbook, but each chunk completes in considerable less time than a chunk on my laptop. With the Python script above for determining the subset of rows to compute, the only variable is the number of instances in the training job configuration, and the subset of rows is automatically computed based on that number.
One thing to note is spot instances might be an option to keep the price down. Checkpoints are configurable in SageMaker jobs, but I did not investigate this at the time.


