
Data Governance | Topics
Stop Blaming Your Data 
godatadriven 21 Dec, 2020





What makes Schiphol Takeoff awesome? Right out of the box Schiphol Takeoff provides a sensible way to deploy your application across different environments!
During our time at Schiphol Group, we built a project which helps automate deployments. Schiphol Group was kind enough to let us open source this project. We’ll give a quick introduction to what it does and how it could help you get to production quicker.
To give a bit more insight into why we built Schiphol Takeoff, it’s good to take a look at an example use case. This use case ties a number of components together:
Conceptually, this is not a very complex setup. However, there are quite a few components involved:
Each of these individually has some form of automation, but there is no unified way of coordinating and orchestrating deployment of the code to all at the same time. If, for example, you were to change the name of the consumer group for Azure Eventhub, you could script that. However, you’d also need to manually update your Spark job running on Databricks to ensure it could still consume the data.
Moreover, this list of components is not complete. These are the components that operate ‘on the foreground’ to deliver the service. Components like Azure Keyvault (for storing secrets), private PyPi repository (for storing Python artifacts), and Azure Blob Storage (for storing artifacts on disk), are not mentioned here, yet play an important role.
Finally, not only does this setup requires quite some configuration to orchestrate the components; in a proper production-like setting, you will probably have more than one environment. Most likely, you’ll have at least a Development and Production environment, to ensure that mistakes by developers (we’re all human after all) don’t affect your end users. This complicates matters even further, because now not only do you need to keep all the components in line, you also need to ensure this happens reliably across environments, without impacting users.
As you can see, without going into deep technical detail of what you would need to do (this would involve a lot of screenshots, yaml, and custom configuration per component), this simple setup results in a complex productionisation, with many pitfalls along the way.
Schiphol Takeoff’s goal is twofold:
To achieve the deployment of the project described in the above, Schiphol Takeoff would require a few things:
We don’t want to make this blogpost a yaml-fest, so we won’t go into details of both these files. If you want to know more, head over to Takeoff’s documentation website or the Github repository.
It is useful, however, to show the Takeoff deployment yaml, as it clearly shows how little a developer would need to do to get things up and running, and to define steps to deploy. Please note that in a “real-world” situation you probably would split up some things into separate repositories (i.e. you probably would have the REST API in a separate repository). This example is purely to demonstrate Takeoff’s capabilities.
steps:
- task: configure_eventhub
create_consumer_groups:
- eventhub_entity: input-eventhub
consumer_group: algorithm-group
create_databricks_secret: true
- eventhub_entity: input-eventhub
consumer_group: rest-sink-group
create_databricks_secret: true
create_producer_policies:
- eventhub_entity: output-eventhub
create_databricks_secret: true
- task: build_artifact
build_tool: python
- task: publish_artifact
language: python
python_file_path: "main/main.py"
target:
- cloud_storage
- task: deploy_to_databricks
jobs:
- main_name: main/main
config_file: databricks.json.j2
lang: python
- task: deploy_to_kubernetes
deployment_config_path: "k8s_config/deployment.yaml.j2"
service_config_path: "k8s_config/service.yaml.j2"These 27 lines (yeah, we counted) are all you need. Every time you commit to your project now, these steps will be run, and will deploy your application per environment (depending on how you’ve setup your deployment configuration).
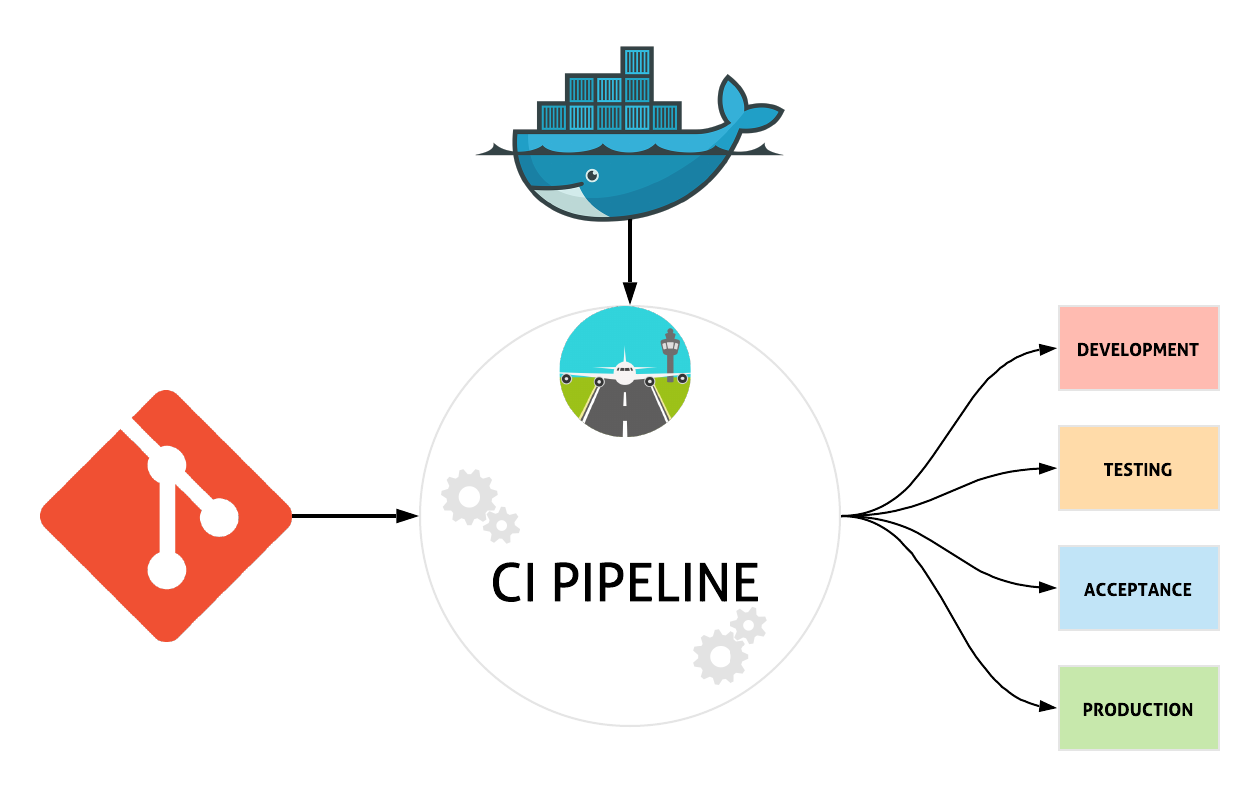
Schiphol Takeoff is a deployment orchestration tool that abstracts away much of the complexity of tying various cloud services together. It allows developers to focus on actual development work, without having to worry about coordinating a (large) number of cloud services to get things up and running across multiple environments. Schiphol Takeoff itself is a Python package and comes bundled in a Docker image. In this way, Schiphol Takeoff is CI agnostic, assuming your CI provider allows running Docker containers. It was developed with a few core principles in mind:
Right out of the box Schiphol Takeoff provides a sensible way to deploy your application across different environments.
Schiphol Takeoff deploys your application to any environment on your cloud. Your CI provider pulls the Schiphol Takeoff image from dockerhub. Schiphol Takeoff then determines what git branch your project is currently on, and using that will decide where the deployment should go. For example, this is how we use Schiphol Takeoff ourselves:
development environment;acceptance;production.It will also make sure versions are preserved during deployment to these environments — given the previous example
development will receive a version equal to the name of your feature branch;acceptance will receive the version SNAPSHOT;production will take the git tag as version.Concretely this means that many feature branches may be running simultaneously, but only one SNAPSHOT or version will be running.
For this all to work, Schiphol Takeoff makes some assumptions about naming conventions. For example, in the case of Microsoft Azure, each of these environments basically mean a separate resource group. These resource groups are identical in the fact that they contain the same services, but otherwise might be different in terms of scaling and naming of services. Based on naming conventions Schiphol Takeoff determines during CI which service in which resource group it should deploy to.
We know that not everyone has the same environments, or might want a different versioning tactic: maybe
acceptance as well;testing.This is where Schiphol Takeoff plugins come in to play. Using Python, we allow you to write your own custom logic regarding what should go where and when. We also allow you to introduce your own naming conventions and logic in the form of a Python plugin.
Schiphol Takeoff was built using Microsoft Azure in mind, as it is the cloud provider used by the Schiphol Data Hub. This means that most services are Azure services, with a few useful exceptions.
However, very important to know is that everything in Schiphol Takeoff was built with modularity in mind. In the future, we hope to be able to support other (cloud) platforms.
Schiphol Takeoff leans heavily on the greatness of Python. It is easy to read, understand and importantly it is very easy to test — unlike bash scripts, makefiles or generic CI configuration which are significantly harder to test (though not impossible). Hence, most* services are deployed using readily available python SDKs.
Thanks to the fact that Schiphol Takeoff runs in Docker, we are fully CI agnostic. Most (if not all) major CI providers are capable of running Docker images and even support Docker-in-Docker (DIND). The latter is needed to make sure Schiphol Takeoff has access to the Docker socket in order to build and push docker images, which it can do! Due to some migrations we’ve had to switch CI providers a few times and found that running Schiphol Takeoff did not change anything in our dependent projects. It generally took around half a day to get to know the new CI provider, setup DIND and everything worked smoothly again!
As mentioned earlier, Schiphol Takeoff was built with Microsoft Azure in mind, but we would like to stress that this does not mean you have to write your own component that deploys kubernetes applications to Google Cloud Platform on Google Kubernetes Engine. In fact, we already support deploying to Azure Kubernetes Service!
Schiphol Takeoff is a deployment automation tool that makes your life easier by taking care of interactions with the various services you may need to bring your application to your users. It allows you to focus on your application, rather than all the (cloud) components you need, and gives you reliable deployments across environments. Of course, we may not support the component or service that you need for your application. Luckily it’s open source, and we’d be thrilled to see contributions (issues, pull requests etc.) to expand Schiphol Takeoff even further. You can find the source code here
We offer a great three-day Data Science with Spark course that teaches you all the ins and outs of using Spark for large-scale data science projects.

