Apache Spark | Data | Domains | Open Source | Python | Technology
Streamlining Data Science Workflows with a Feature Catalog 
Roel Bertens 09 Feb, 2023





I recently discovered Kedro, a Python data engineering and science framework. When I played with it, I discovered it is built around some interesting design choices. The design choice that stood out the most to me is its decoupling between the data and pipeline logic. This choice might not sound like a big deal, but it results in some unexpected benefits I did not expect. In this blog post, I’ll discuss how Kedro achieves this decoupling and the benefits it can bring to your data science workflow.
In a typical data science project, you will spend much time writing IO code. For example, the data set downloading and parsing code or the code that handles the input and output of your pipeline steps. If you are not very rigorous about this, your IO code grows wild and becomes scattered throughout your project. All this scattered IO code makes it hard to keep track of all the data flowing through your project, and it makes it hard to reuse this code. Initially, you might think this is not a big deal, but it can become a significant maintenance problem once your project grows.
Kedro avoids the scattered IO logic problem by collecting all the IO and data-related logic in a single place, which they call the data catalog. As a result, you only need to write the IO logic once, and you can reuse it throughout your project. Most of the time, you don’t need to write this IO logic yourself because Kedro has implementations for most common data types and storage systems. This makes it very easy to get started with the data catalog. Another advantage of having all this IO logic in one place is that it becomes very easy to register and track all the data and artifacts used in your project. All you need to do is provide Kedro with the following information, and Kedro will know how to load or write that data:
In a Kedro project, you typically provide all this information in a YAML configuration. For example, you can register a CSV dataset and a pickle model artifact by adding the following to the conf/base/catalog.yml file:
# A CSV file stored locally
iris:
type: pandas.CSVDataSet
filepath: data/01_raw/iris.csv
# A pickle sklearn model stored in Azure blob storage
model:
type: pickle.PickleDataSet
filepath: abfs://data/06_models/model.pkl
credentials: azure_storageAll this configuration to be able to read and write data sounds like a lot of work, but it is powerful. Thanks to the data catalog, we can load or save our data using declarative rather than imperative code. In declarative code, you only tell the computer what to do instead of how to do it. This change simplifies the code you need to write significantly. For example, loading and saving a dataset becomes as simple as:
your_dataset = catalog.load("<dataset_name>")
... # Do something fancy using your data
catalog.save(your_updated_dataset, "<dataset_name>")This change might sound trivial, but this has some interesting and unexpected benefits for your data science workflow.
In a Kedro project, "It works on my machine" is no longer a concern. With a shared data catalog, everyone accesses data in the same way by simply knowing the name of the dataset. The big advantage here is that it eliminates the need for manual data sharing and ensures consistency across the team. For example, to access a colleague’s preprocessed data, you only need to know the name of the dataset. The same goes for artifacts, such as trained models. The data catalog takes away all the hassle of sharing data and ensures that everyone accesses the data in the same way. This is especially a big advantage for team members that are less familiar with cloud based workflows. They don’t need to learn all the ins and outs of your cloud storage, they only need to know the name of the dataset.
In a production-ready data science project, reproducibility is a key aspect. To achieve this, pipelines are often run on cloud computing platforms such as AzureML or SageMaker. While this is great for ensuring reproducibility, it can be challenging to perform a quick, one-off analysis in a notebook. For instance, accessing preprocessed data and trained models might not be straightforward. However, with a shared data catalog, this becomes much easier. The intermediate data and artifacts are registered in the data catalog, making them easily accessible. If you start up a notebook server using kedro jupyter notebook, the data catalog is already created for you, and you can access it using the catalog variable. To perform an analysis, you only need to request the desired data or artifacts from the data catalog.
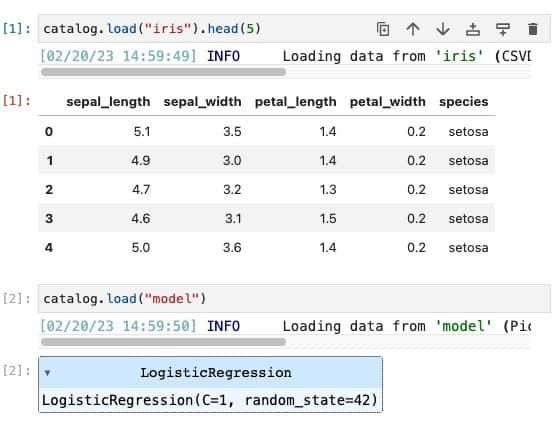
The big advantage here is that you can quickly perform a one-off analysis, which can increase your debugging and analysis speed significantly.
Most pipeline steps are typically filled with all kinds of IO code. In Kedro pipeline steps, this is not the case because the data catalog handles all the IO logic. The big advantage here is that you can focus on writing a normal Python function that takes some input and returns some output. The data catalog can then ensure that the inputs are provided and that the outputs are saved. This approach enables you to create pure functions that are simpler to test and maintain. For example, if your function receives a pandas DataFrame as input, you can quickly unit test it by providing a dummy DataFrame. You no longer need to worry about abstracting or mocking away your IO code, which simplifies the testing process. This not only improves the maintainability of your pipeline steps but also makes it easier to get started with testing, which helps ensure that your pipeline steps work as expected and remain maintainable over time.
So far I have been very impressed by Kedro’s data catalog. It is a powerful tool that can greatly enhance your data science workflow. It’s important to note that the data catalog can only be used within a Kedro project due to its specific repository setup. Sadly, Kedro has a bit of learning curve. However, the benefits of using Kedro make it worth considering for your project. If you’re interested in learning how to use Kedro, we have some project templates and tutorials to get you started.
