Data | Domains
Keep Learning 
GoDataDriven 13 May, 2020





From credit ratings to housing allocation, machine learning models are increasingly used to automate ‘everyday’ decision making processes. With the growing impact on society, more and more concerns are being voiced about the loss of transparency, accountability and fairness of the algorithms making the decisions. We as data scientists need to step-up our game and look for ways to mitigate emergent discrimination in our models. We need to make sure that our predictions do not disproportionately hurt people with certain sensitive characteristics (e.g., gender, ethnicity).
Luckily, last year’s NIPS conference showed that the field is actively investigating how to bring fairness to predictive models. The number of papers published on the topic is rapidly increasing, a signal that fairness is finally being taken seriously. This point is also nicely made in the cartoon below, which was taken from the excellent CS 294: Fairness in Machine Learning course taught at UC Berkley.

Some approaches focus on interpretability and transparency by allowing deeper interrogation of complex, black box models. Other approaches, make trained models more robust and fair in their predictions by taking the route of constraining and changing the optimization objective. We will consider the latter approach and show how adversarial networks can bring fairness to our predictive models.
In this blog post, we will train a model for making income level predictions, analyse the fairness of its predictions and then show how adversarial training can be used to make it fair. The used approach is based on the 2017 NIPS paper "Learning to Pivot with Adversarial Networks" by Louppe et al.
Note that most of the code has been omitted, you can find the Jupyter notebook with all the code here.
Let’s start by training a basic classifier that can predict whether or not a person’s income is larger than 50K dollar a year. Too make these income level predictions we turn to the adult UCI dataset, which is also referred to as "Census Income" dataset. It is not hard to imagine that financial institutions train models on similar data sets and use them to decide whether or not someone is eligible for a loan, or to set the height of an insurance premium.
Before training a model, we first parse the data into three datasets: features, targets and sensitive attributes. The set of features X contains the input attributes that the model uses for making the predictions, with attributes like age, education level and occupation. The targets y contain the binary class labels that the model needs to predict. These labels are y\in\left\{income>50K, income\leq 50K\right\}. Finally, the set of sensitive attributes Z contains the attributes for which we want the prediction to fair. These are z_{race}\in\left\{black, white\right\} and z_{sex}\in\left\{male, female\right\}.
It is important to note that datasets are non-overlapping, so the sensitive attributes race and sex are not part of the features used for training the model.
# load ICU data set
X, y, Z = load_ICU_data('data/adult.data')
> features X: 30940 samples, 94 attributes
> targets y: 30940 samples
> sensitives Z: 30940 samples, 2 attributesOur dataset contains the information of just over 30K people. Next, we split the data into train and test sets, where the split is 50/50, and scale the features X using standard scaling.
# split into train/test set
X_train, X_test, y_train, y_test, Z_train, Z_test = train_test_split(X, y, Z, test_size=0.5,
stratify=y, random_state=7)
# standardize the data
scaler = StandardScaler().fit(X_train)
scale_df = lambda df, scaler: pd.DataFrame(scaler.transform(df), columns=df.columns, index=df.index)
X_train = X_train.pipe(scale_df, scaler)
X_test = X_test.pipe(scale_df, scaler)Now, let’s train our basic income level predictor. We use Keras to fit a simple three-layer network with ReLU activations and dropout on the training data. The output of the network is a single node with sigmoid activation, so it predicts "the probability that this person’s income is larger than 50K".
def nn_classifier(n_features):
inputs = Input(shape=(n_features,))
dense1 = Dense(32, activation='relu')(inputs)
dropout1 = Dropout(0.2)(dense1)
dense2 = Dense(32, activation='relu')(dropout1)
dropout2 = Dropout(0.2)(dense2)
dense3 = Dense(32, activation="relu")(dropout2)
dropout3 = Dropout(0.2)(dense3)
outputs = Dense(1, activation='sigmoid')(dropout3)
model = Model(inputs=[inputs], outputs=[outputs])
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
# initialise NeuralNet Classifier
clf = nn_classifier(n_features=X_train.shape[1])
# train on train set
history = clf.fit(X_train, y_train, epochs=20, verbose=0)Finally, we use this classifier to make income level predictions on the test data. We determine the model performance by computing the Area Under the Curve and the accuracy score using test set predictions.
# predict on test set
y_pred = pd.Series(clf.predict(X_test).ravel(), index=y_test.index)
print(f"ROC AUC: {roc_auc_score(y_test, y_pred):.2f}")
print(f"Accuracy: {100*accuracy_score(y_test, (y_pred>0.5)):.1f}%")
> ROC AUC: 0.91
> Accuracy: 85.1%With a ROC AUC larger than 0.9 and a prediction accuracy of 85% we can say that our basic classifier performs pretty well! However, if it is also fair in its predictions, that remains to be seen.
We start the investigation into the fairness of our classifier by analysing the predictions it made on the test set. The plots in the figure below show the distributions of the predicted P(income>50K) given the sensitive attributes.
fig = plot_distributions(y_pred, Z_test, fname='/wp-content/images/biased_training.png')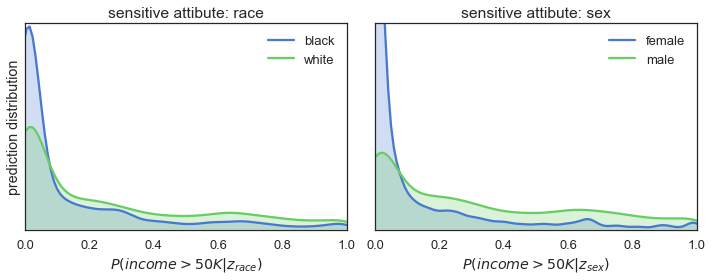
The figure shows for both race (=left plot) and sex (=right plot) the blue prediction distributions have a large peak at the low end of the probability range. This means that when a person is black and/or female there is a much higher probability of the classifier predicting an income below 50K compared to when someone is white and/or male.
So, the results of the qualitative analysis are quite clear: the predictions are definitely not fair when considered in the context of race and sex. When it comes to assigning the high-income levels, our model favours the usual suspects: white males.
In order to get a ‘quantitative’ measure of how fair our classifier is, we take inspiration from the U.S. Equal Employment Opportunity Commission (EEOC). They use the so-called 80% rule to quantify the disparate impact on a group of people of a protected characteristic. Zafar et al. show in their paper "Fairness Constraints: Mechanisms for Fair Classification" how a more generic version of this rule, called the p%-rule, can be used to quantify fairness of a classifier. This rule is defined as follows:
A classifier that makes a binary class prediction \hat{y} \in \left\{0,1 \right\} given a binary sensitive attribute z\in \left\{0,1 \right\} satisfies the p%-rule
if the following inequality holds:
\min\left(\frac{P(\hat{y}=1|z=1)}{P(\hat{y}=1|z=0)}, \frac{P(\hat{y}=1|z=0)}{P(\hat{y}=1|z=1)}\right)\geq\frac{p}{100}The rule states that the ratio between the probability of a positive outcome given the sensitive attribute being true and the same probability given the sensitive attribute being false is no less than p:100. So, when a classifier is completely fair it will satisfy a 100%-rule. In contrast, when it is completely unfair it satisfies a %0-rule.
In determining the fairness our or classifier we will follow the EEOC and say that a model is fair when it satisfies at least an 80%-rule. So, let’s compute the p%-rules for the classifier and put a number on its fairness. Note that we will threshold our classifier at 0.5 to make its prediction it binary.
print("The classifier satisfies the following %p-rules:")
print(f"\tgiven attribute race; {p_rule(y_pred, Z_test['race']):.0f}%-rule")
print(f"\tgiven attribute sex; {p_rule(y_pred, Z_test['sex']):.0f}%-rule")
> The classifier satisfies the following %p-rules:
> given attribute race; 45%-rule
> given attribute sex; 32%-ruleWe find that for both sensitive attributes the classifier satisfies a p%-rule that is significantly lower than 80%. This supports our earlier conclusion that the trained classifier is unfair in making its predictions.
It is important to stress that training a fair model is not straightforward. One might be tempted to think that simply removing sensitive information from the training data is enough. Our classifier did not have access to the race and sex attributes and still we ended up with a model that is biased against women and black people. This begs the question: what caused our classifier to behave this way?
The observed behaviour is most likely caused by biases in the training data. To understand how this works, consider the following two examples of image classification errors:

The classifier that made these errors was trained on data in which some ethnic and racial minorities are overrepresented by small number of classes. For example, black people are often shown playing basketball and Asian people playing ping-pong. The model picks up on these biases and uses them for making predictions. However, once unleashed into the wild it will encounter images in which these minorities are doing things other than playing basketball or ping-pong. Still relying on its learned biases, the model can misclassify these images in quite painful ways.
Now, the UCI dataset, used for training our classifier, has similar kinds of biases in the data. The dataset is based on census data from 1994, a time in which income inequality was just as much of an issue as it is nowadays. Not surprisingly, most of the high earners in the data are white males, while women and black people are more often part of the low-income group. Our predictive model can indirectly learn these biases, for example, through characteristics like education level and zip-code of residence. As a result, we end-up with the unfair predictions observed in previous section, even after having removed the race and sex attributes.
How can we go about fixing this issue? In general, there are two approaches we can take. We can somehow try to de-bias the dataset, for example by adding additional data that comes from a more representative sample. Alternatively, we can constrain the model so that it is forced into making fairer predictions. In the next section, we will show how adversarial networks can help in taking the second approach.
In 2014, Goodfellow et al. published their seminal paper on Generative Adversarial Networks (GANs). They introduce GANs as a system of two neural networks, a generative model and an adversarial classifier, which are competing with each other in a zero-sum game. In the game, the generative model focusses on producing samples that are indistinguishable from real data, while the adversarial classifier tries to identify if samples came from the generative model or from the real data. Both networks are trained simultaneously such that the first improves at producing realistic samples, while the second becomes better at spotting the fakes from the real. The figure below shows some examples of images that were generated by a GAN:

Our procedure for training a fair income classifier takes inspiration from GANs: it leverages adversarial networks to enforce the so-called pivotal property on the predictive model. This statistical property assures that the outcome distribution of the model no longer depends on so-called nuisance parameters. These parameters are not of immediate interest, but must be accounted for in a statistical analysis. By taking the sensitive attributes as our nuisance parameters we can enforce predictions that are independent of, in our case, race and sex. This is exactly what we need for making fair predictions!
The starting point for adversarial training our classifier is the extension of the original network architecture with an adversarial component. The figure below shows what this extended architecture looks like:
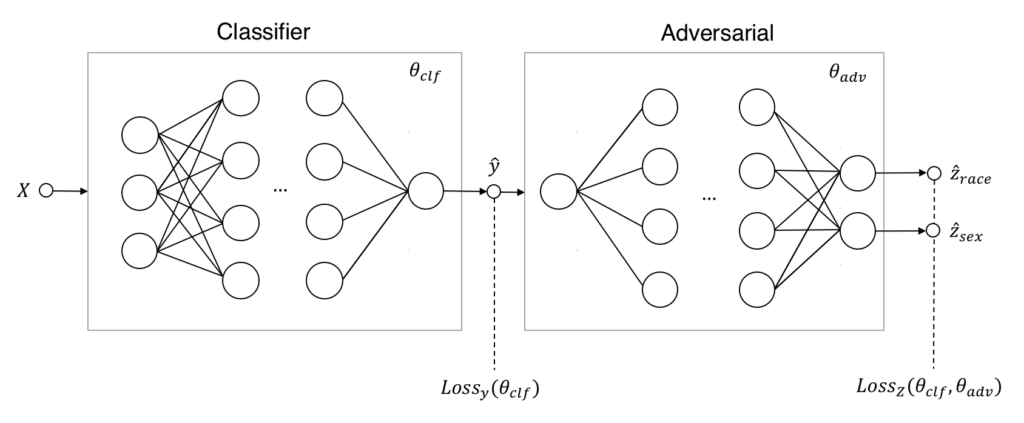
At first glance, this system of two neural networks looks very similar to the one used for training GANs. However, there are some key differences. First, the generative model has been replaced by a predictive model. So, instead of generating synthetic data it now generates actual predictions \hat{y} based on the input X. Second, the task of the adversarial is no longer to distinguish real from generated data. Instead, it predicts the sensitive attribute values \hat{z}\in\hat{Z} from the predicted \hat{y} of the classifier. Finally, the objectives that both nets try to optimize are based on the prediction losses of the target and sensitive attributes, these are denoted by Loss<em>{y}(\theta</em>{clf}) and Loss<em>{Z}(\theta</em>{clf},\theta_{adv}) in the figure.
Let’s consider the nature of the zero-sum game the classifier and adversarial are engaged in. For the classifier the objective of twofold: make the best possible income level predictions whilst ensuring that race or sex cannot be derived from them. This is captured by the following objective function:
\min_{\theta_{clf}}\left[Loss_{y}(\theta_{clf})-\lambda Loss_{Z}(\theta_{clf},\theta_{adv})\right].So, it learns to minimize its own prediction losses while maximizing that of the adversarial (due to \lambda being positive and minimizing a negated loss is the same as maximizing it). Note that increasing the size of \lambda steers the classifier towards fairer predictions while sacrificing prediction accuracy. The objective during the game is simpler For the adversarial: predict race and sex based on the income level predictions of the classifier. This is captured in the following objective function:
\min_{\theta_{adv}}\left[Loss_{Z}(\theta_{clf},\theta_{adv})\right].The adversarial does not care about the prediction accuracy of the classifier. It is only concerned with minimizing its own prediction losses.
Now that our classifier is upgraded with an adversarial component, we turn to the adversarial training procedure. In short, we can summarize this procedure in the following 3 steps:
T iterations simultaneously train the adversarial and classifier networks:The actual adversarial training starts only after the first two pre-training steps. It is then that the training procedure mimics the zero-sum game during which our classifier will (hopefully) learn how make predictions that are both accurate and fair.
Finally, we are ready to adverserial train a fair classifier. We kick-off by initializing our newly upgraded classifier and pre-train both the classifier and adverserial networks:
# initialise FairClassifier
clf = FairClassifier(n_features=X_train.shape[1], n_sensitive=Z_train.shape[1],
lambdas=[130., 30.])
# pre-train both adverserial and classifier networks
clf.pretrain(X_train, y_train, Z_train, verbose=0, epochs=5)The supplied \lambda values, that tune fairness versus accuracy, are set to \lambda_{race}=130 and \lambda_{sex}=30. We heuristically found that these settings result in a balanced increase of the p%-rule values during training. Apparently, it is slightly harder to enforce fairness for the racial attributes than for sex.
Now that both networks have been pre-trained, the adversarial training can start. We will simultaneously train both networks for 165 iterations while tracking the performance of the classifier on the test data:
# adverserial train on train set and validate on test set
clf.fit(X_train, y_train, Z_train,
validation_data=(X_test, y_test, Z_test),
T_iter=165, save_figs=True)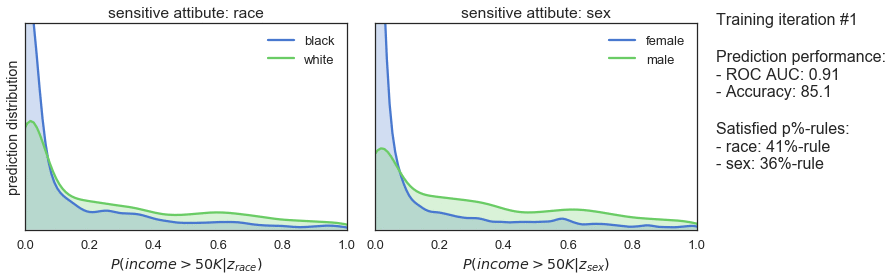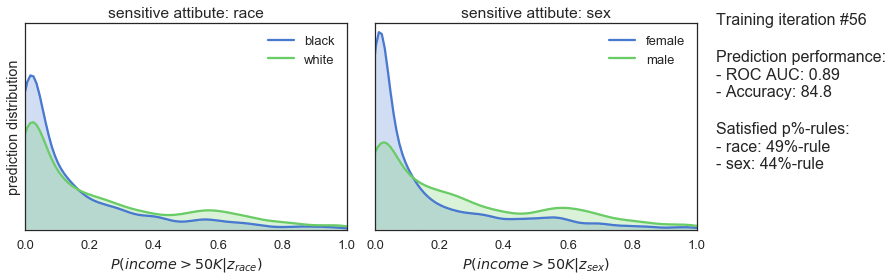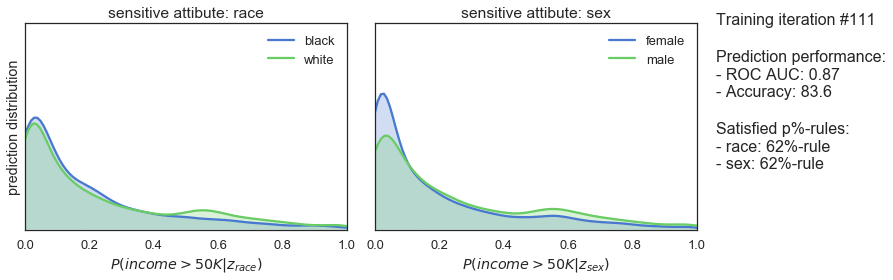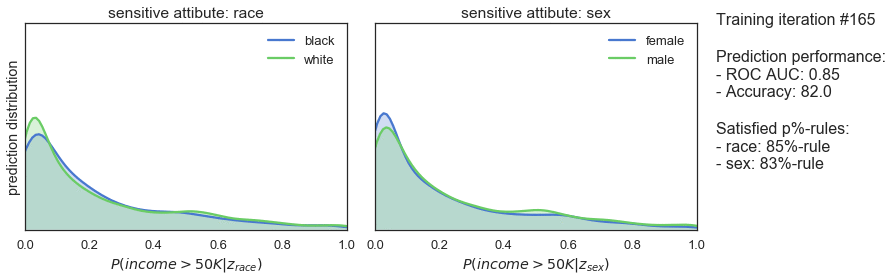
The plots above show how the prediction distributions, the satisfied p%-rules and the prediction performance of our classifier evolve during adversarial training. At iteration #1, when training is just starting out, the predictions are very much the same as observed for the previously trained classifier: both high in bias and in prediction performance. As the training progresses, we see that the predictions are gradually become more and more fair while prediction performance is slightly declining. Finally, after 165 iterations of training, we see that the classifier satisfies the 80%-rule for both sensitive attributes while achieving a ROC AUC 0.85 and an accuracy of 82%.
So, it seems that the training procedure works quite well. After sacrificing only 7% of prediction performance, we end up with a classifier that makes fair predictions when it comes to race and sex. A pretty decent result!
In this blog post we have shown that bringing fairness to predictive models is not as straight forward as ‘just’ removing some sensitive attributes from the training data. It requires clever techniques, like adverserial training, to correct for the often deeply biased training data and force our models into making fair predictions. And yes, making fair predictions comes at a cost: it will reduce the performance of your model (hopefully, only by a little as was the case in our example). However, in many cases this will be a relatively small price to pay for leaving behind the biased world of yesterday and predicting our way into a fairer tomorrow!
Shout-out to Henk who was so kind to review this work and provide his comments!
At GoDataDriven we offer a host of Python courses taught by the very best professionals in the field. Join us and level up your Python game:
