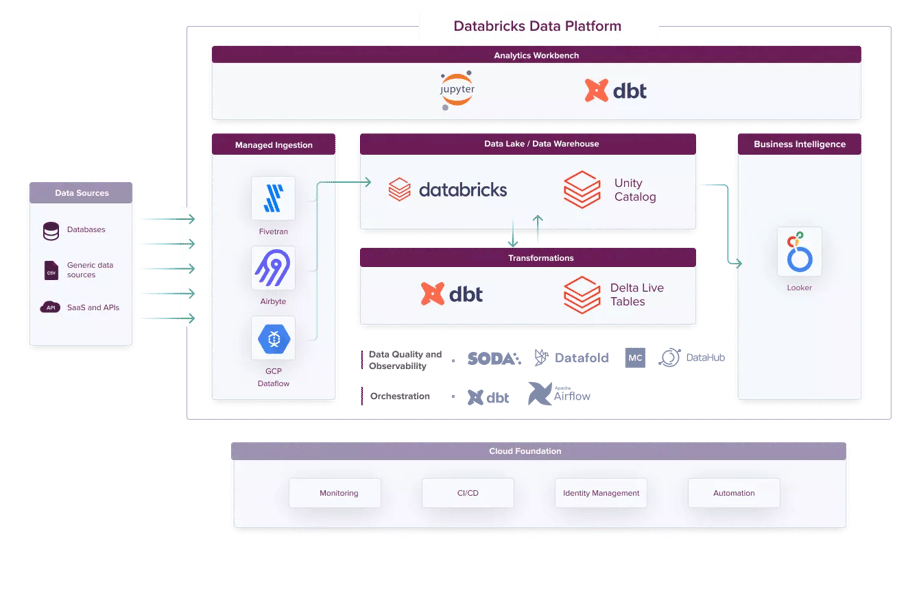
The Databricks Data Platform is a tailored-to-fit solution built using proven, cutting-edge components that support any data application, from near real-time dashboarding to complex AI products.
The Databricks Data Platform has been designed and developed based on decades of experience with the implementation of scalable infrastructure for the enterprise. It offers fast implementation and seamless integration, without compromising the ability to overcome any real-world data challenge.
The Databricks Data Platform is part of Xebia Base, our suite of tailored-to-fit platforms.
![]()
Technologies Used
To build the Databricks Data Platform we combine the best cloud-native and Databricks services. Our Data Engineers carefully select the most suitable tools, creating a stable, user-friendly, and scalable platform.
Installation Process
The platform is deployed using pre-configured modules based on infrastructure as code, allowing users to run and maintain the platform independently.
Enviroments
The Databricks Data Platform runs natively on:
- GCP
- Azure
- AWS
The platform modular design allows us to tailor it to client needs and existing technologies.


The Architecture of the Databricks Data Platform
It’s our ambition to implement the best data solutions as efficiently as possible. Based on our years of experience, we have created a platform that can be adapted quickly. The result for our clients is a shorter time-to-market and a greater competitive edge. The solution is cloud-agnostic, mixing the best cloud services with Databricks technologies.